uCore文件系统
文件系统
整体逻辑
graph BT
%% 核心模块:easy-fs(文件系统核心逻辑)
subgraph easy-fs ["easy-fs(文件系统核心算法)"]
direction BT
subgraph BD ["抽象层:BlockDevice(块设备接口)"]
direction TB
read_block("read_block")
write_block("write_block")
end
subgraph BC ["缓存层:BlockCache(块缓存)"]
direction TB
read("read")
modify("modify")
bc_other("其他缓存操作...")
end
subgraph LAY ["布局层:存储结构定义"]
direction TB
SB("SuperBlock(超级块)")
BM("Bitmap(位图)")
DI("DiskInode(磁盘索引节点)")
DE("DirEntry(目录项)")
DB("DataBlock(数据块)")
end
subgraph BMGR ["管理层:文件系统实例/接口"]
direction TB
EFS("EasyFileSystem(文件系统实例)")
INODE("Inode(文件/目录操作接口)")
end
%% easy-fs 内部链路(修正方向)
BD -->|读写物理块| BC
BC -->|缓存读写| LAY
LAY -->|基于布局实现| BMGR
end
%% 辅助工具:easy-fs 配套工具(宿主机侧)
subgraph easy-fs-tools ["easy-fs-tools(宿主机工具)"]
direction TB
pack("easy_fs_pack(打包工具)")
fuse("easy-fs-fuse(FUSE调试工具)")
end
easy-fs -->|依赖核心逻辑| pack
pack -->|生成镜像| fs_img["fs.img(raw格式镜像)"]
easy-fs -->|适配FUSE接口| fuse
fuse -->|挂载调试| fs_img
%% QEMU(虚拟硬件层)
subgraph qemu ["QEMU(虚拟硬件)"]
direction TB
drive("-drive file=fs.img(后端存储)")
virtio_dev("-device virtio-blk-device(虚拟块设备)")
end
fs_img -->|作为后端存储| drive
drive -->|绑定到虚拟设备| virtio_dev
%% os 内核(驱动+文件系统调用)
subgraph os ["os(内核层)"]
direction TB
subgraph VIRTIO ["驱动层:VirtIOBlock"]
direction TB
virtio_bd("实现 BlockDevice 接口")
virtio_ops("virtio-blk 读写操作")
end
subgraph FS_CALL ["应用层:文件系统调用"]
direction TB
fs_open("open/read/write")
fs_exec("执行ELF文件")
end
end
%% 内核链路
qemu -->|暴露虚拟硬件| virtio_dev
virtio_dev -->|内核枚举设备| VIRTIO
VIRTIO -->|适配接口| easy-fs
easy-fs -->|提供文件操作| FS_CALL文件与文件描述符
文件简介
这个接口在内存和I/O资源之间建立了数据交换的通道。其中
UserBuffer 是我们在 mm
子模块中定义的应用地址空间中的一段缓冲区,我们可以将它看成一个
&[u8] 切片。
1 | // os/src/fs/mod.rs |
UserBuffer
的声明如下,此外,我们还让它作为一个迭代器可以逐字节进行读写,参考
Iterator和IntoIterator
1 | // os/src/mm/page_table.rs |
标准输入和标准输出
我们定义标准输入和标准输出分别为 Stdin 和
Stdout
1 | /// stdin file for getting chars from console |
并为他们实现 File 接口
1 | impl File for Stdin { |
文件描述符与文件描述符表
- 每个进程包含了一个
文件描述符表,包含了所有打开的文件; 文件描述符表的每一项都是一个文件描述符,文件描述符是一个非负整数,表示文件描述符表中一个打开的 文件描述符 所处的位置;- 使用
open()或者create()打开或创建一个文件时,内核会返回给应用刚刚打开或创建的文件对应的文件描述符; - 使用
close()关闭文件时,需要提供相应的文件描述符。 文件描述符表在进程内是pub fd_table: Vec<Option<Arc<dyn File + Send + Sync>>>,这里值得注意的是,他的索引是fd,值是我们分配的文件OSInode。
文件I/O操作
关于 dyn 的解析,参考 dyn
1 | pub struct TaskControlBlockInner { |
Vec的动态长度特性使得我们无需设置一个固定的文件描述符数量上限;Option使得我们可以区分一个文件描述符当前是否空闲,当它是None的时候是空闲的,而Some则代表它已被占用;Arc首先提供了共享引用能力。后面我们会提到,可能会有多个进程共享同一个文件对它进行读写。此外被它包裹的内容会被放到内核堆而不是栈上,于是它便不需要在编译期有着确定的大小;dyn关键字表明Arc里面的类型实现了File/Send/Sync三个 Trait ,但是编译期无法知道它具体是哪个类型(可能是任何实现了FileTrait 的类型如Stdin/Stdout,故而它所占的空间大小自然也无法确定),需要等到运行时才能知道它的具体类型。
当新建一个进程的时候,我们需要按照先前的说明为进程打开标准输入文件和标准输出文件:
1 | impl TaskControlBlock { |
文件读写系统调用
基于文件读写的系统调用更加灵活了,我们在当前进程的文件描述符表中通过文件描述符找到某个文件,无需关心文件具体的类型,只要知道它一定实现了
File Trait 的 read/write 方法即可。Trait
对象提供的运行时多态能力会在运行的时候帮助我们定位到
read/write 的符合实际类型的实现。
对比一下新版本和旧版本我们可以发现:
- 旧版本的
sys_write()是基于虚拟内存地址找到对应的物理内存地址,并将buf输出到标准输出; - 新版本的
sys_write()是基于文件描述符找到对应的文件,并将buf输出到标准输出;
旧版本
1 | pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize { |
新版本
1 | pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize { |
简易文件系统 easy-fs (上)
松耦合模块化设计思路
easy-fs是简易文件系统的本体;easy-fs-fuse是能在开发环境(如 Ubuntu)中运行的应用程序,用于将应用打包为 easy-fs 格式的文件系统镜像,也可以用来对easy-fs进行测试。
easy-fs crate
以层次化思路设计,自下而上可以分成五个层次:
- 磁盘块设备接口层:以块为单位对磁盘块设备进行读写的 trait
接口,对应抽象接口
BlockDevice,为块驱动设备提供了read_block()和write_block()方法用于读写块设备; - 块缓存层:在内存中缓存磁盘块的数据,避免频繁读写磁盘,对应
BlockCache。为上层提供了以下方法:addr_of_offset可以得到一个BlockCache内部的缓冲区中指定偏移量offset的字节地址;get_ref可以获取缓冲区中的位于偏移量offset的一个类型为T的磁盘上数据结构的不可变引用;- 和
get_ref一致,只是获取到可变引用。
- 磁盘数据结构层:磁盘上的超级块、位图、索引节点、数据块、目录项等核心数据结构和相关处理;
- 磁盘块管理器层:合并了上述核心数据结构和磁盘布局所形成的磁盘文件系统数据结构
- 索引节点层:管理索引节点,实现了文件创建/文件打开/文件读写等成员函数
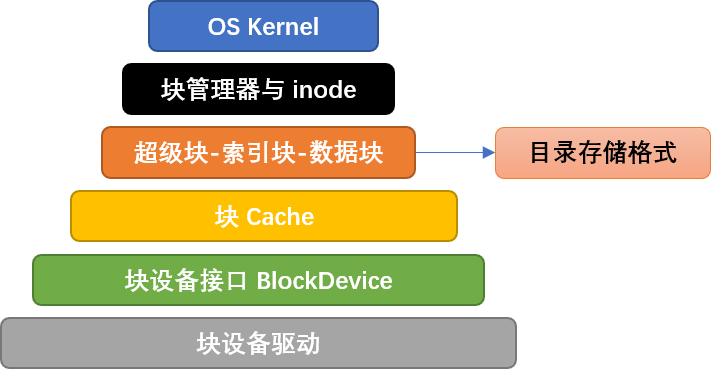
目前来看,一个文件系统的设计可以分为五层,我们先看底下的三层,他们分别是:
- BlockDevice 它是对底层存储硬件(磁盘 / 模拟磁盘)的抽象接口,向上为 BlockCache 层提供统一的「按块读写」接口(
read_block/write_block),向下由具体硬件驱动实现(如物理磁盘驱动、内存模拟磁盘驱动)—— 核心是屏蔽不同硬件的读写差异,让上层无需关心硬件类型。- BlockCache 这一层是对持久化设备的缓存,它将持久化设备中存储的数据缓存到内存中:
- 他在
new()的时候通过BlockDevice的接口读取并初始化数据到内存,随后所有的读操作都通过操作 BlockCache 内存中的数据实现;- 当数据写入到 BlockCache 时,只是更新了内存中的数据,我们需要通过 sync 来调用 BlockDevice 的写接口,来将数据写入到持久化存储;
- 他需要提供策略来淘汰对持久化设备的缓存映射;
- 同一个物理块在内存中只会有一个 BlockCache 实例(通过哈希表 / 全局管理),避免多副本不一致;
- 通过
modify方法(如你之前看到的代码)封装 “读缓存→修改内存→可选刷盘” 的原子操作,保证缓存数据的一致性;
- 磁盘数据结构层,到这里我们已经不再关注对于持久化设备的读写,而开始关注到数据的组织。这一层,我们将持久化设备看做一个连续的空间并将他划分为多个等大小的块,我们通过超级块,索引位图,索引节点,数据块位图,数据块节点来合理的分配/回收我们的持久化设备资源。
块设备接口层
在 easy-fs 库的最底层声明了块设备的抽象接口
BlockDevice
,这个对应了我们五个层次的最底层,由块驱动设备来实现对应的调用逻辑。
1 | pub trait BlockDevice : Send + Sync + Any { |
块cache层
块缓存(BlockCache)
BlockCache
封装了对磁盘块的引用,提供了读/写相关的方法,需要注意的是,BlockCache
在退出的时候,需要保证将修改回写到磁盘,我们通过RAII实现:
1 | // easy-fs/src/block_cache.rs |
块缓存全局管理器
在实际应用中,硬盘的大小远超内存大小,所以我们需要一个全局的管理器来管理我们的块缓存,他需要满足如下需求:
- 检查某个块是否已经被加载到缓存;
- 加载块到缓存;
- 在超过设定的限制时,提供策略对缓存进行淘汰;
我们通过一个 FIFO
的队列来实现这个逻辑:块缓存的类型是一个
Arc<Mutex<BlockCache>> ,这是 Rust
中的经典组合,它可以同时提供共享引用和互斥访问。这里的共享引用意义在于块缓存既需要在管理器
BlockCacheManager
保留一个引用,还需要将引用返回给块缓存的请求者。而互斥访问在单核上的意义在于提供内部可变性通过编译,在多核环境下则可以帮助我们避免可能的并发冲突。
1 | use alloc::collections::VecDeque; |
1 | impl BlockCacheManager { |
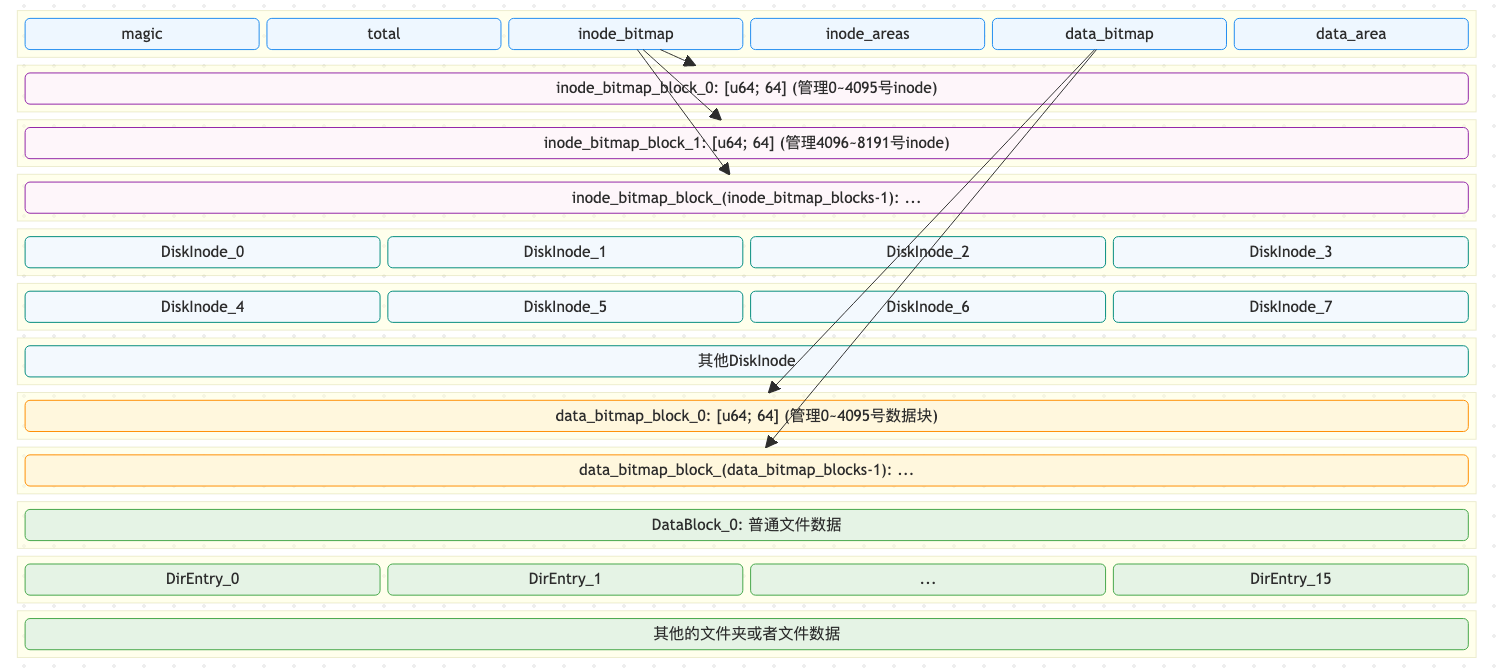
磁盘布局及磁盘上数据结构
磁盘数据结构层的代码在
layout.rs和bitmap.rs中
easy-fs 磁盘按照块编号从小到大顺序分成 5 个连续区域:
- 第一个区域只包括一个块,它是 超级块 (Super Block),用于定位其他连续区域的位置,检查文件系统合法性。
- 第二个区域是一个索引节点位图,长度为若干个块。它记录了索引节点区域中有哪些索引节点已经被分配出去使用了。
- 第三个区域是索引节点区域,长度为若干个块。其中的每个块都存储了若干个索引节点。
- 第四个区域是一个数据块位图,长度为若干个块。它记录了后面的数据块区域中有哪些已经被分配出去使用了。
- 最后的区域则是数据块区域,其中的每个被分配出去的块保存了文件或目录的具体内容。
他们的物理布局为:
- 第一个区域对应的是
SuperBlock - 第二个区域对应的是
BitmapBlock:[u64; 64],在运行时通过Bitmap的一个实例来管理元数据(start_block_id, blocks); - 第三个区域对应的是索引节点区域,对应的是
DiskInode,记录了文件大小,文件类型以及他们所分布的block位置;同时还是用IndirectBlock抽象了对一级索引,二级索引的访问; - 第四个区域对应的是
BitmapBlock:[u64; 64],在运行时通过Bitmap的一个实例来管理元数据(start_block_id, blocks); - 最后一个区域是数据块区域,对应于
DataBlock = [u8; BLOCK_SZ]和DirEntry。
File和Directory都以 DiskInode 的形式存储在文件系统中。
文件系统逻辑
文件系统启动初始化(核心是加载位图管理工具)
- 启动文件系统,从磁盘第 0 块(超级块专属块)读取
SuperBlock; - 从
SuperBlock中提取关键元数据:inode_bitmap_start_block(inode 位图区域起始物理块号)、inode_bitmap_blocks(inode 位图总块数);data_bitmap_start_block(数据位图区域起始物理块号)、data_bitmap_blocks(数据位图总块数);inode_area_start_block(inode 区域起始物理块号)、data_area_start_block(数据块区域起始物理块号);
- 用上述元数据初始化两个
Bitmap管理对象:这两个对象仅存在于内存,用于后续分配 / 回收 inode / 数据块;inode_bitmap = Bitmap::new(inode_bitmap_start_block, inode_bitmap_blocks);data_bitmap = Bitmap::new(data_bitmap_start_block, data_bitmap_blocks);
根目录
/的解析(文件系统的 “入口逻辑”):这里有个前提是,文件系统固化约定inode_id == 0为根目录的 inode 编号(不可修改的入口);
- 计算根目录 inode 所在的物理块号:root_inode_block_id = inode_area_start_block + (0 / inodes_per_block);
- 读取
root_inode_block_id对应的磁盘块,解析出第 0 个DiskInode(即root_inode):- 校验:
root_inode.type_ == InodeType::Dir(必须是目录类型,否则文件系统异常);
- 校验:
- 从
root_inode中提取direct/indirect字段(指向 data_areas 中的物理块号); - 读取这些 data_areas 块,解析成
DirEntry数组(root_entries)—— 这就是根目录下的所有文件 / 子目录; - 遍历 root_entries 中的每个 DirEntry(root_entry):
- 每个 root_entry 包含 name(文件名 / 目录名) + inode_number(该文件 / 目录的 inode_id);
- 若 root_entry 对应普通文件:
- 用 inode_number 重复步骤 2-3,读取该文件的 DiskInode(类型为 InodeType::File);
- 从该 DiskInode 的 direct/indirect 字段读取 data_areas 块,解析出文件原始数据;
- 若 root_entry 对应子目录(如 /home):
- 用 inode_number 递归执行阶段 2 的逻辑(从步骤 2 开始),解析该子目录下的 DirEntry 列表;
文件查找
| 层级 | 存储内容 | 核心作用 | 存储位置 |
|---|---|---|---|
| 1. 目录项(DirEntry) | 文件名、对应 inode_id | 实现 “文件名 → inode_id” 的映射(按名查找核心) | 上级目录的 DataBlock |
| 2. 文件 inode(DiskInode) | 修改时间、权限、大小、数据块指针 | 存储文件所有元数据,关联数据块 | inode_areas |
| 3. 数据块(DataBlock) | 文件实际内容(如文本、二进制数据) | 存储文件的原始数据 | data_areas |
- 对于目录类型的
DiskInode(Directory),它不存储任何 “内容”,仅存储「指向存储子文件 DirEntry 数组的 DataBlock 指针」;子文件的文件名 + inode_id 实际存储在该 DataBlock 的 DirEntry 数组中。 - 对于文件类型的
DiskInode(File),它也不存储文件实际内容,仅存储「指向文件内容 DataBlock 的指针 + 文件元数据(时间 / 权限 / 大小等)」;文件实际内容存储在 DataBlock 中。
可以理解为,不管是什么类型的 DiskInode,他们都只是一个指针,只不过类型不同:
- DiskInode(Directory) ->
Vec<DirEntry>- DiskInode(File) ->
Vec<DataBlock>
我们一个实际的文件,会分为两个部分:
- 文件的元数据信息,包含了文件名和inode_id。这个信息存放在
DirEntry中,它的上级目录会通过DiskInode指向一个DirEntry数组,数组中包含了该文件夹下的全部文件; - 文件的数据信息,这个信息存放在
DataBlock下,通过<1>中的DirEntry::inode_id可以找到一个DiskInode,这个查找到的DiskInode的 block_id 指向了他们实际所处的DataBlock。- 这里需要注意的是,
DirEntry信息只是为了实现到子文件的映射;如果我们需要存储类似于修改时间,权限之类的文件元数据信息,存放到文件对应的DiskInode是一个更好的选择。
- 这里需要注意的是,
我们一个实际的文件(先忽略文件夹类型)应该是这样找到的:
- 首先通过 DiskInode(Directory类型) 在 data_areas 中找到对应的 DirEntry;
- 通过 DirEntry 找到文件对应的 DiskInode(File类型);
- 通过 DiskInode(File类型)到 data_areas 找到对应的 DataBlock;
以查找 /text.txt 为例:
graph TD
A[根目录inode(DiskInode,inode_id=0)] -->|1.读取其指向的Data Block| B[目录项列表(DirEntry数组)]
B -->|"2.查找name='test.txt'的DirEntry"| C[DirEntry(name=test.txt, inode_id=10)]
C -->|3.通过inode_id=10计算物理位置| D[文件inode(DiskInode,类型=File)]
D -->|4.读取其direct/indirect指针| E[Data Block(存储test.txt的实际内容)]Bitmap
1 | /// A bitmap |
这里 Bitmap
最开始是一个困惑了我很久的地方,最后我才明白:Bitmap { start_block_id: 1, blocks: N }
是运行时管理工具,仅用于定位 inode_bitmap
区域的物理块,不持久化;
我们的实际输出布局应该为:
SuperBlock -> BitmapBlock_0 --> ... -> BitmapBlock_
inode_bitmap_blocks - 1--> DiskInode_0 --> ... --> DiskInode_inode_bitmap_blocks * 16--> BitmapBlock_0 --> ... --> BitmapBlock_data_bitmap_blocks - 1-->DataBlock or DirEntry--> ...
在初始化一个文件系统时,可以指定 inode_bitmap_blocks 表示总的 inode_bitmap 的数量。
当我们初始化完成后,我们整体的输出布局就确定了,并且这个值会被初始化到 SuperBlock::inode_bitmap_blocks。
当下次我们再次启动时,我们首先读取 SuperBlock::inode_bitmap_blocks,这样我们就可以知道我们当前的文件系统中的 inode_bitmap 的数量。
block-beta
columns 8
classDef superBlockField fill:#f0f8ff,stroke:#2196f3,stroke-width:1px,rounded:6px;
classDef inodeBitmapField fill:#fef7fb,stroke:#9c27b0,stroke-width:1px,rounded:4px;
classDef diskInodeField fill:#f5fafe,stroke:#009688,stroke-width:1px,rounded:4px;
classDef dataBitmapField fill:#fff8e1,stroke:#ff9800,stroke-width:1px,rounded:4px;
classDef dataBlockField fill:#e8f5e8,stroke:#4caf50,stroke-width:1px,rounded:4px;
classDef transparent fill:none,stroke:none,shadow:none,border:none;
block:SuperBlock:16
magic("magic")
total_blocks("total")
inode_bitmap_blocks("inode_bitmap")
inode_area_blocks("inode_areas")
data_bitmap_blocks("data_bitmap")
data_area_blocks("data_area")
end
class magic superBlockField
class total_blocks superBlockField
class inode_bitmap_blocks superBlockField
class inode_area_blocks superBlockField
class data_bitmap_blocks superBlockField
class data_area_blocks superBlockField
block:inode_bitmap0:16
BitmapBlock_0("inode_bitmap_block_0: [u64; 64] (管理0~4095号inode)")
end
class BitmapBlock_0 inodeBitmapField
block:inode_bitmap1:16
BitmapBlock_1("inode_bitmap_block_1: [u64; 64] (管理4096~8191号inode)")
end
class BitmapBlock_1 inodeBitmapField
block:inode_bitmapN:16
BitmapBlock_N("inode_bitmap_block_(inode_bitmap_blocks-1): ...")
end
class BitmapBlock_N inodeBitmapField
block:inode0:16
DiskInode_0("DiskInode_0"):1
DiskInode_1("DiskInode_1"):1
DiskInode_2("DiskInode_2"):1
DiskInode_3("DiskInode_3"):1
end
class DiskInode_0 diskInodeField
class DiskInode_1 diskInodeField
class DiskInode_2 diskInodeField
class DiskInode_3 diskInodeField
block:inode1:16
DiskInode_4("DiskInode_4"):1
DiskInode_5("DiskInode_5"):1
DiskInode_6("DiskInode_6"):1
DiskInode_7("DiskInode_7"):1
end
class DiskInode_4 diskInodeField
class DiskInode_5 diskInodeField
class DiskInode_6 diskInodeField
class DiskInode_7 diskInodeField
block:inode2:16
DiskInode_8("其他DiskInode"):1
end
class DiskInode_8 diskInodeField
block:data_bitmap0:16
BitmapBlock_1_0("data_bitmap_block_0: [u64; 64] (管理0~4095号数据块)")
end
class BitmapBlock_1_0 dataBitmapField
block:data_bitmapN:16
BitmapBlock_1_N("data_bitmap_block_(data_bitmap_blocks-1): ...")
end
class BitmapBlock_1_N dataBitmapField
block:data0:16
DataBlock_0("DataBlock_0: 普通文件数据")
end
class DataBlock_0 dataBlockField
block:data1:16
Dir0("DirEntry_0")
Dir1("DirEntry_1")
Dir2("...")
Dir15("DirEntry_15")
end
class Dir0 dataBlockField
class Dir1 dataBlockField
class Dir2 dataBlockField
class Dir15 dataBlockField
block:data2:16
DataBlock("其他的文件夹或者文件数据")
end
class DataBlock dataBlockField
inode_bitmap_blocks --> inode_bitmap0
inode_bitmap_blocks --> inode_bitmap1
inode_bitmap_blocks --> inode_bitmapN
data_bitmap_blocks --> data_bitmap0
data_bitmap_blocks --> data_bitmapN
class 1 transparenteasy-fs 超级块
1 | // easy-fs/src/layout.rs |
位图
位图是一个特殊的数据结构,他的实现如下:
1 | // easy-fs/src/bitmap.rs |
但是这里需要注意的一个重点是:
Bitmap是文件系统的运行时管理工具,在我们的实际存储中并没有这个对象。他在初始化时被写入到 SuperBlock,在加载时从 SuperBlock 生成;BitmapBlock是存储实际位图的结构,他通过[u64; 64]映射了4096 bit/512B。
当我们需要分配inode节点时:
- 在所有的位图block中,从前往后搜索;
- 每个位图block被抽象为一个
[u64; 64],我们搜索block就是搜索这个数组,如果数组中某个数字不为u64::Max,那么说明我们找到了一个空闲的inode; - 将对应的位设置为
1,那么我们也就完成了对于inode的分配,我们返回分配的位在整个 blocks 中的比特位偏移,假设这个值为inode_id:block_id= start_of_inode_area_block_id + (inode_id / inodes_per_block);new_inode_block_offset= (inode_id % inodes_per_block) *core::mem::size_of::<DiskInode>();
详细请参考 inode_id和block_id
1 | impl Bitmap { |
释放 bit 的代码如下:
- 通过block在自身的areas的相对偏移量 --
这里对于data节点是相对于data_area_start_block的偏移量,对于inode节点是相对于inode_area_start_block的偏移量,计算得到block偏移量,在
[u64;64]中的偏移量,在u64中的偏移量。 - 通过以上三个指标将对应的bit位设置为
0。
1 | /// Decompose bits into (block_pos, bits64_pos, inner_pos) |
磁盘上索引节点(DiskInode)
DiskInode 是将我们的实际存储节点 DataBlock
和 DirEntry
组织为真正文件系统的索引。因为一个文件/文件夹通常会使用不止一个块,并且零散的分布在整个持久化系统中。通过
DiskInode
我们才知道文件/文件夹的大小,类型以及分布在哪些地方。
他的作用有一点类似于 MemorySet
中的页表,可以将一个逻辑上连续但物理上不连续的空间(也就是文件/文件夹),映射到物理离散的
DataBlock/DirEntry(持久化设备)。
flowchart TB
subgraph DiskInode
subgraph direct
block_id_0("block id 0")
block_id_1("block id 1")
block_id_2("...")
block_id_n("block id 27")
end
indirect1("indirect1"):::purple
indirect2("indirect2"):::purple
end
IndirectBlock1("IndirectBlock<br/>[u32; BLOCK_SZ / 4]")
IndirectBlock2("IndirectBlock<br/>[u32; BLOCK_SZ / 4]")
IndirectBlock3("IndirectBlock<br/>[u32; BLOCK_SZ / 4]")
IndirectBlock4("...")
subgraph block_1
DataBlock1("DataBlock - 01")
DataBlock2("DataBlock - 02")
end
subgraph block_2
DataBlock3("DataBlock - 03")
end
subgraph block_3
DataBlock4("DataBlock - 04")
end
subgraph block_4
DataBlock5("...")
end
subgraph block_5
DataBlock7("DataBlock - 27")
end
block_id_0 --> DataBlock1
block_id_1 --> DataBlock2
block_id_2 --> DataBlock3
block_id_2 --> DataBlock4
block_id_2 --> DataBlock5
block_id_n --> DataBlock7
indirect1 --> IndirectBlock1 --> MoreBlock
indirect2 -->|二级间接| IndirectBlock2
IndirectBlock2 -->|一级间接| IndirectBlock3 --> MoreBlock
IndirectBlock2 -->|一级间接| IndirectBlock4 --> MoreBlock
subgraph MoreBlock
direction TB
DataBlock8("DataBlock - 28")
DataBlock9("DataBlock - 29")
DataBlock10("...")
end
DataBlock1:::green
DataBlock2:::green
DataBlock3:::green
DataBlock4:::green
DataBlock5:::green
DataBlock7:::green
DataBlock8:::green
DataBlock9:::green
DataBlock10:::green
block_id_0:::pink
block_id_1:::pink
block_id_2:::pink
block_id_n:::pink
IndirectBlock1:::error
IndirectBlock2:::error
IndirectBlock3:::error
IndirectBlock4:::error
classDef pink 1,fill:#FFCCCC,stroke:#333, color: #fff, font-weight:bold;
classDef green fill: #696,color: #fff,font-weight: bold;
classDef purple fill:#969,stroke:#333, font-weight: bold;
classDef error fill:#bbf,stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
classDef coral fill:#f9f,stroke:#333,stroke-width:4px;
classDef animate stroke-dasharray: 9,5,stroke-dashoffset: 900,animation: dash 25s linear infinite;我们首先需要一些解析节点元数据的方法:
1 | impl InodeDisk { |
get_block_id 方法体现了 DiskInode
最重要的数据块索引功能,它将文件内的索引编号 inner_id
转换为实际的
block_id,试想假设我们需要读取一个文件,那么一定会有一个输入参数
offset 表示他在文件内的偏移量。我们需要经历 offset
-> inner_block_id --> block_id
才能获取到实际的物理存储位置。
1 | impl DiskInode { |
read_at
再回到我们前面提到的读文件,我们通过 read_at
来对外暴露该能力,这里整体逻辑非常简单:
- 使用
offset作为start,offset + buf.len()与min(self.size)的较小值作为end。 - 通过
offset查找到物理block_id; - 在循环中,我们取
end_of_current_block和end的较小值作为结束地址,并读取数据到buf,直到数据读取完毕。
整体的逻辑非常简单,但是在实现上有两个非常值得注意的优化:
- 在决定读取的区间范围时,使用
offset + buf.len()与min(self.size)的较小值作为end,这可以避免我们在后续的读取操作时需要去判断边界条件 -- 本次循环是读满buf还是读到了文件结束。 - 在循环中,我们取
end_of_current_block和end的较小值作为结束地址,这个优化和上面的优化是一个思路,避免判断边界条件 -- 是读到block完毕还是读到end。 - 整体来说就是,每次读取时我们先找到最小的限制值作为我们的end,避免复杂的边界条件判断。
1 | impl DiskInode { |
目录项
对于文件而言,它的内容在文件系统或内核看来没有任何既定的格式,只是一个字节序列。目录的内容却需要遵从一种特殊的格式,它可以看成一个目录项的序列,每个目录项都是一个二元组,包括目录下文件的文件名和索引节点编号。目录项
DirEntry 的定义如下:
1 | // easy-fs/src/layout.rs |
简易文件系统 easy-fs (下)
磁盘块管理器
本层的代码在
efs.rs中。
EasyFileSystem
的定义非常简单,包含了我们前面提到的两个Bitmap内存管理块以及inode_are和data_area的开始block索引。这些信息都可以在启动的时候,通过
SuperBlock 来解析。
1 | // easy-fs/src/efs.rs |
他的实现逻辑如下:
- 通过
total_blocks,inode_bitmap_blocks我们可以计算得到inode_area_blocks,data_bitmap_blocks,data_area_blocks,使用这些信息,初始化全部的文件系统元数据; - 在我们的
inode_id == 0的inode_areas中初始化根目录。
1 | impl EasyFileSystem { |
如果已经已经写入了 easy-fs
的镜像,我们可以直接使用静态方法 EasyFileSystem::open
方法打开:
1 | impl EasyFileSystem { |
inode 和 data
的分配也由他负责,这里值得注意的几个点是:
allo_inode返回的是inode_id,而alloc_data返回的是block_id。这里我个人认为应该是一个实现上的小失误,因为它同样提供了get_data_block_id方法来通过data_block_id来计算真实的block_id,只不过没有使用上;dealloc_data将block_id对应的block数据设置为0,并且释放data_bitmap中的 bit;- 没有实现
inode的回收逻辑。
1 | impl EasyFileSystem { |
索引节点
efs
实现了磁盘布局并将素有的块管理起来,但是实际使用中用户并不关注实际的块的布局,为此我们设计索引节点
Inode
暴露给文件系统的使用者,让他们能够直接对文件和目录进行操作。
Inode 和 DiskInode
的区别从它们的名字中就可以看出: DiskInode
放在磁盘块中比较固定的位置,而 Inode
是放在内存中的记录文件索引节点信息的数据结构。
1 | // easy-fs/src/vfs.rs |
再回忆一下我们的 DiskInode
节点,他是一个位于某个block的结构,一个 block 中可能有多个
DiskInode,所以我们需要:
block_id指定它的物理存储 block;block_offset制定他在他所位于的 block 的 offset;fs是一个EasyFileSystem的指针,我们对Inode的操作,最终是通过封装EasyFileSystem的接口来实现的;
获取根目录的 inode
1 | impl EasyFileSystem { |
EasyFileSystem的互斥锁
我们在 Inode 中基本所有的操作都是基于内部的
EasyFileSystem
实例来操作的,所有的暴露给文件系统的文件操作接口 -- 也就是
Inode 中的 pub 方法,都是全程持有
EasyFileSystem 的互斥锁的。而他内部的
private
方法,默认调用者已经获取到互斥锁了。
这是一种比较常用的锁设计:
- 当一个对象,他可能并发的访问一个资源时,它所有的
pub方法全程持有互斥锁,内部的private方法因为不会对外暴露,所以可以约定调用者已经获持有互斥锁; - 一个会尝试持有锁的方法不能访问另一个持有锁的方法:这会导致死锁。
这种锁设计模式是并发编程中非常经典且实用的 “分层锁管理” 范式(也叫 “锁边界约定”)。
创建文件
文件的创建不复杂:
- 如果文件已经存在则直接返回;
- 否则,先初始化
inode节点,这个节点将用于指向我们的实际文件; - 将文件的
DirEntry添加到当前目录的inode中;- 这里需要注意的是,我们的
DiskInode的结构,他也是一个典型的逻辑上连续,物理上不连续的结构,所以他可能需要进行扩容,可以参考 increase
- 这里需要注意的是,我们的
- 写入数据到持久化设备。
1 | impl Inode { |
将应用打包为 easy-fs 镜像
BlockFile
BlockFile 通过 File 实现了对接
1 | struct BlockFile(Mutex<File>); |
easy-fs-fuse
在第六章我们需要将所有的应用都连接到内核,随后通过
get_app_by_name 搜索 elf
文件,这样会导致内核体积过大。我们可以通过将这些应用打包到 easy-fs
镜像中放到磁盘中,当我们要执行应用的时候只需从文件系统中取出ELF
执行文件格式的应用 并加载到内存中执行即可。
- source 存放输入文件的源码;
- target 存放编译后的二进制文件;
- 创建一个镜像文件
fs.img,读取全部的二进制文件,按照我们前面定义的文件系统格式存放到fs.img。后续我们会将该镜像文件挂在到qemu作为操作系统的内核文件。
1 | fn easy_fs_pack() -> std::io::Result<()> { |
在内核中使用 easy-fs
块设备驱动层
在 qemu 上,我们使用 VirtIOBlock 访问 VirtIO
块设备,并将它全局实例化为 BLOCK_DEVICE
,使内核的其他模块可以访问。
1 | // os/src/drivers/block/mod.rs |
在启动 Qemu 模拟器的时候,我们可以配置参数来添加一块 VirtIO 块设备:
1 | FS_IMG := ../user/target/$(TARGET)/$(MODE)/fs.img |
-drive定义一个磁盘镜像文件,但暂时不直接挂载到虚拟机file=$(FS_IMG)指定磁盘镜像文件的路径;if=nonif = interface(接口),none 表示 “不直接将这个磁盘挂载到任何虚拟机内置接口”(如 ide/sata),仅作为 “后端资源” 等待绑定;format=raw指定镜像文件的格式为 raw(裸格式)—— 无任何封装,数据直接存储,是最简单的磁盘格式;id=x0给这个后端磁盘分配唯一标识 x0,后续可通过这个 ID 将其绑定到具体的虚拟设备上;
-device创建虚拟块设备并绑定后端磁盘virtio-blk-device指定要创建的虚拟设备类型为virtio-blkdrive=x0将这个 virtio 块设备绑定到之前定义的、ID 为 x0 的磁盘后端(即FS_IMG镜像);bus=virtio-mmio-bus.0指定设备挂载到虚拟机内的virtio-mmio-bus.0总线
内核索引节点层
内核将 easy-fs 提供的 Inode 进一步封装为 OS
中的索引节点 OSInode 。
1 | // os/src/fs/inode.rs |
文件系统相关内核机制实现
文件系统初始化
经过我们的努力,现在我们的内核只需要和 EasyFileSystem
以及 BLOCK_DEVICE 交互:
EasyFileSystem为我们实现了文件系统的整体布局,缓存,算法等;BLOCK_DEVICE则为我们屏蔽了不同硬件下的差异。
| 抽象层 | 核心作用 | 解决的核心问题 |
|---|---|---|
EasyFileSystem |
封装文件系统的逻辑层 | 内核无需关心
“文件系统如何组织元数据(SuperBlock/Bitmap/DiskInode)、如何缓存块、如何映射目录和文件”,只需调用
Inode 的 open/read/write 等接口; |
BLOCK_DEVICE(BlockDevice trait) |
封装存储的硬件层 | 内核无需关心 “底层是 virtio-blk、SATA、NVMe 还是文件模拟”,只需实现
read_block/write_block 接口,就能对接任意块设备; |
1 | // os/src/fs/inode.rs |
文件系统相关内核机制实现
通过 sys_open 打开文件
- 如果指定了创建文件标识
- 文件不存在则创建;
- 文件存在则直接删除原文件;
- 如果没有指定创建文件标识
- 没有找到对应文件返回
None; - 如果找到文件:
- 如果指定了
TRUNC则截断原文件; - 否则返回原文件。
- 如果指定了
- 没有找到对应文件返回
1 | /// Open a file |
通过 sys_exec 执行文件
这个逻辑非常简单,没必要单独说了。
1 | pub fn sys_exec(path: *const u8) -> isize { |
QA
等待处理的问题
- 画一下内核,进程,文件描述符,文件之间的关系;
- 整个
easy-fs,easy-fs-fuse,kernel是如何交互,以及组织起来的; - 整个内核的五层是如何交互起来的;
block_id这里指的块是?什么是块?- 画一个图,表示
easy-fs的磁盘布局。 - 直接指针,一级间接索引,二级间接索引的示意图;
- 分析
increase_size和clear_size的实现; - 分析
read_at和write_at的实现; DirEntry和File/Directory是如何关联起来的?- 实现文件索引支持DIRECTORY的递归;
- 搞清楚磁盘的块的定义已经操作。
代码树
1 | ├── easy-fs(新增:从内核中独立出来的一个简单的文件系统 EasyFileSystem 的实现) |
代码统计
1 | ➜ 2025a-rcore-0x822a5b87 git:(ch6) cloc os easy-fs |
磁盘的块
我们在实现文件系统的逻辑的时候,通常会将文件系统划分为block。
假设存在如下场景,一个block上存储了一个 DiskInode
1 |
|
那么此时,如果我们要更新 ref_count,那么我们有以下两种方式:
- 计算ref_count所在的位置并更新;
- 修改 DiskInode 结构体,并更新DiskInode所在的块。
这两个速度是不是理论上差不多?因为磁盘的最小操作是block。
文件系统的完整模型
| 模块 | 核心职责 | 关键接口 / 产物 |
|---|---|---|
easy-fs |
实现文件系统核心算法逻辑(SuperBlock/bitmap/inode/DataBlock
管理),定义 BlockDevice 抽象接口(解耦 “文件系统逻辑” 和
“底层存储”) |
BlockDevice
trait、EasyFileSystem、Inode |
easy-fs-fuse |
宿主机工具:读取编译后的 ELF 二进制文件,基于 easy-fs
逻辑生成 fs.img 镜像(文件系统的 “物理存储载体”) |
fs.img(16MiB raw 格式镜像,包含 ELF 文件) |
os |
内核层:实现 virtio-blk 块设备驱动(适配
BlockDevice 接口),基于驱动构造
EasyFileSystem,对外提供文件操作接口 |
VirtioBlockDevice(实现
BlockDevice)、内核文件操作 API |
QEMU |
启动时将 fs.img 挂载为 virtio-blk
虚拟块设备,为内核提供 “物理存储”,完成 “镜像→块设备→文件系统”
的落地 |
-drive file=fs.img、-device virtio-blk-device |
increase_size
inode_id和block_id
inode_id是inode_bitmap中的全局比特位偏移(也是inode_areas中 inode 的 “全局编号”);block_id是磁盘的物理偏移量。
我们可以通过 SuperBlock 的元数据 + inode_id
计算得到:block_id = start_of_inode_area_block_id +
(inode_id / inodes_per_block);
五层模型
block-beta
columns 14
space:5
block:tag1:4
kernel("OS kernel")
end
space:5
space:4
block:tag2:6
block_manager("块管理器与inode")
end
space:4
space:3
block:tag3:8
disk_structure("超级块-索引块-数据块")
end
space:3
space:2
block:tag4:10
cache("块cache")
end
space:2
space:1
block:tag5:12
block_device("块设备接口 BlockDevice")
end
space:1
block:tag6:14
driver("块设备驱动")
end
classDef transparent fill:none,stroke:none,shadow:none,border:none;
class tag1,tag2,tag3,tag4,tag5,tag6 transparentBlockCache的类型推导
在
rust中,泛型参数会沿着调用链传递,直到调用方提供具体类型标注,编译器才会完成最终的类型实例化;
我们注意到 BlockCache 有两个关键的泛型函数:
1 | impl BlockCahce { |
在这个两个泛型函数中,我们分别返回了 &T 和
&mut T,在此基础之上,我们封装了额外的调用:
1 | impl BlockCache { |
在封装的函数中,我们有一个lambda函数
impl FnOnce(&T) -> V
作为参数,但是他也是一个泛型函数。此时,它的类型仍然是泛型的。
在随后的函数调用中,我们有如下代码:
1 | /// An indirect block |
在这里,编译器才真正的可以通过类型推导得出:
T-> IndirectBlockV-> u32
BitmapBlock的迭代
在 Bitmap 的 alloc
中,我们可以看到如下代码:
1 | impl Bitmap { |
这里有一个点是,我们的 bits64 是一个
&&u64 类型。
bitmap_block.iter()返回一个迭代器,其中每个元素的类型是&u64(对数组中u64元素的引用)。这是因为iter()方法会生成一个共享引用迭代器,用于只读访问元素。- **
enumerate():当调用enumerate()时,迭代器的元素会被包装成(索引, 原元素)的元组。因此,元组中第二个元素的类型仍然是&u64(继承自iter()的元素类型)。 - 闭包参数的解构:在
find(|(_, bits64)| ...)中,闭包的参数是对元组(usize, &u64)的引用(即&(usize, &u64))。当通过模式(_, bits64)解构时,bits64会被自动解引用一次,但由于原元素是&u64,因此最终bits64的类型会是&&u64(对&u64的引用)。
这里值得注意的是,如果是 (idx, bits64) 的形式,那么
idx 的类型会是 &usize。
dyn
Rust 语法卡片:Rust 中的多态
在编程语言中, 多态 (Polymorphism) 指的是在同一段代码中可以隐含多种不同类型的特征。在 Rust 中主要通过泛型和 Trait 来实现多态。
- 泛型是一种 编译期多态 (Static Polymorphism),在编译一个泛型函数的时候,编译器会对于所有可能用到的类型进行实例化并对应生成一个版本的汇编代码,在编译期就能知道选取哪个版本并确定函数地址,这可能会导致生成的二进制文件体积较大;
- 而 Trait 对象(也即上面提到的
dyn语法)是一种 运行时多态 (Dynamic Polymorphism),需要在运行时查一种类似于 C++ 中的 虚表 (Virtual Table) 才能找到实际类型对于抽象接口实现的函数地址并进行调用,这样会带来一定的运行时开销,但是更为灵活。
dyn的作用是什么
dyn 是 Rust 中用于标记动态分发 trait 对象(Trait
Object) 的关键字,在
Arc<dyn File + Send + Sync> 里,它的核心作用是
“告诉编译器:这个 Arc 包裹的不是某个具体类型,而是实现了
File + Send + Sync 这些 trait
的任意类型”,他的核心作用是:
- 标记 “trait 对象”,实现动态分发(运行时才确定具体调用哪个类型的方法);
- 把 “实现了某 trait 的具体类型” 抽象成 “trait 本身”,让代码能兼容多种不同类型(只要它们实现了对应的 trait);
- 在
Arc<dyn File + Send + Sync>中,dyn File + Send + Sync表示 “任意实现了Filetrait,且满足Send/Sync线程安全的类型”。
为什么需要dyn?
Rust 有两种 trait 调用方式:
无dyn表示静态分发,编译时确定类型;dyn表示动态分发,运行时确定类型。
dyn的一些关键特性
- 大小不固定(DST):
dyn File是 “动态大小类型(DST)”,无法直接创建实例(let f: dyn File = FileA;报错),必须包裹在指针里(&dyn File/Box<dyn File>/Arc<dyn File>)。 - 动态分发的代价:
- 优点:灵活,支持运行时切换类型;
- 缺点:有轻微性能开销(运行时查 vtable),且无法调用 trait 的关联函数(只能调用方法)。
- trait 约束:只有满足 “对象安全(Object Safe)” 的
trait 才能用
dyn,核心规则:- 方法不能是静态方法(无
&self/&mut self); - 方法不能返回
Self(因为Self是具体类型,dyn无法确定);
- 方法不能是静态方法(无
Iterator和IntoIterator
IntoIterator 和 Iterator 是 Rust
中遍历集合的两个核心 trait:
IntoIterator负责 “把一个类型转换成迭代器”Iterator负责 “定义迭代的具体行为”
flowchart LR
struct("struct"):::green
IntoIteratorInstance("struct转换为Iterator"):::purple
IteratorInstance("迭代操作"):::purple
struct -.->|IntoIterator| IntoIteratorInstance -.->|Iterator| IteratorInstance
classDef pink 1,fill:#FFCCCC,stroke:#333, color: #fff, font-weight:bold;
classDef green fill: #696,color: #fff,font-weight: bold;
classDef purple fill:#969,stroke:#333, font-weight: bold;
classDef error fill:#bbf,stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
classDef coral fill:#f9f,stroke:#333,stroke-width:4px;
classDef animate stroke-dasharray: 9,5,stroke-dashoffset: 900,animation: dash 25s linear infinite;Iterator
Iterator
的定义相当复杂,但是实际上,我们需要做的事只有两个:
type Item = *mut u8来定义 trait 的关联类型(Associated Type),详细解析可以参考 关联类型和泛型参数;next()函数;
1 |
|
IntoIterator
IntoIterator 解决的问题是:如何把一个
“集合类型”(如 Vec<T>)转换成 “迭代器类型”(如
std::vec::IntoIter<T>),我们需要的有三步:
Item对迭代的类型进行类型关联;IntoIter对迭代器的类型进行类型关联;fn into_iter()方法进行类型迭代;
1 | impl IntoIterator for UserBuffer { |
关联类型和泛型参数
关联类型 和 泛型参数有相似的 “类型抽象”
作用,但本质是两种不同的 Rust 语法机制。他们最大的区别在于:
- 关联类型:在 trait 内部
声明(
type Item;),一个类型对 trait 的单次实现只能绑定一种具体类型(比如为VecIter实现Iterator,Item只能是i32或String,二选一); - 泛型参数:在 trait/impl/ 函数
名称后
声明(
<T>),一个类型对 trait 的单次实现可适配任意类型(比如impl<T> MyTrait<T> for MyType,T可以是i32/String/ 任意类型),编译器会为每种实际使用的类型生成单独的函数版本(单态化)。
为什么我们在迭代器里使用关联类型而不是泛型参数呢?
迭代器的语义就是天然只能产出一种元素,这个和关联类型是天然匹配的,例如,假设我们使用泛型参数来实现迭代器:
1 | struct Vec<T>(Vec<T>); |
但是,我们甚至可以为它实现一个单独的迭代器来违反这个语义:
1 | impl Iterator<String> for Vec<i32> { |
而这种语义在使用关联类型时是非法的,以下的代码没有办法通过编译:
1 | impl Iterator for UserBufferIterator { |
但是在迭代器中,我们仍然可以为它实现一个泛型的迭代器,只是通过关联类型避免了我们刚才提到的问题:
1 | struct Hello<T> where T : Copy { |